|
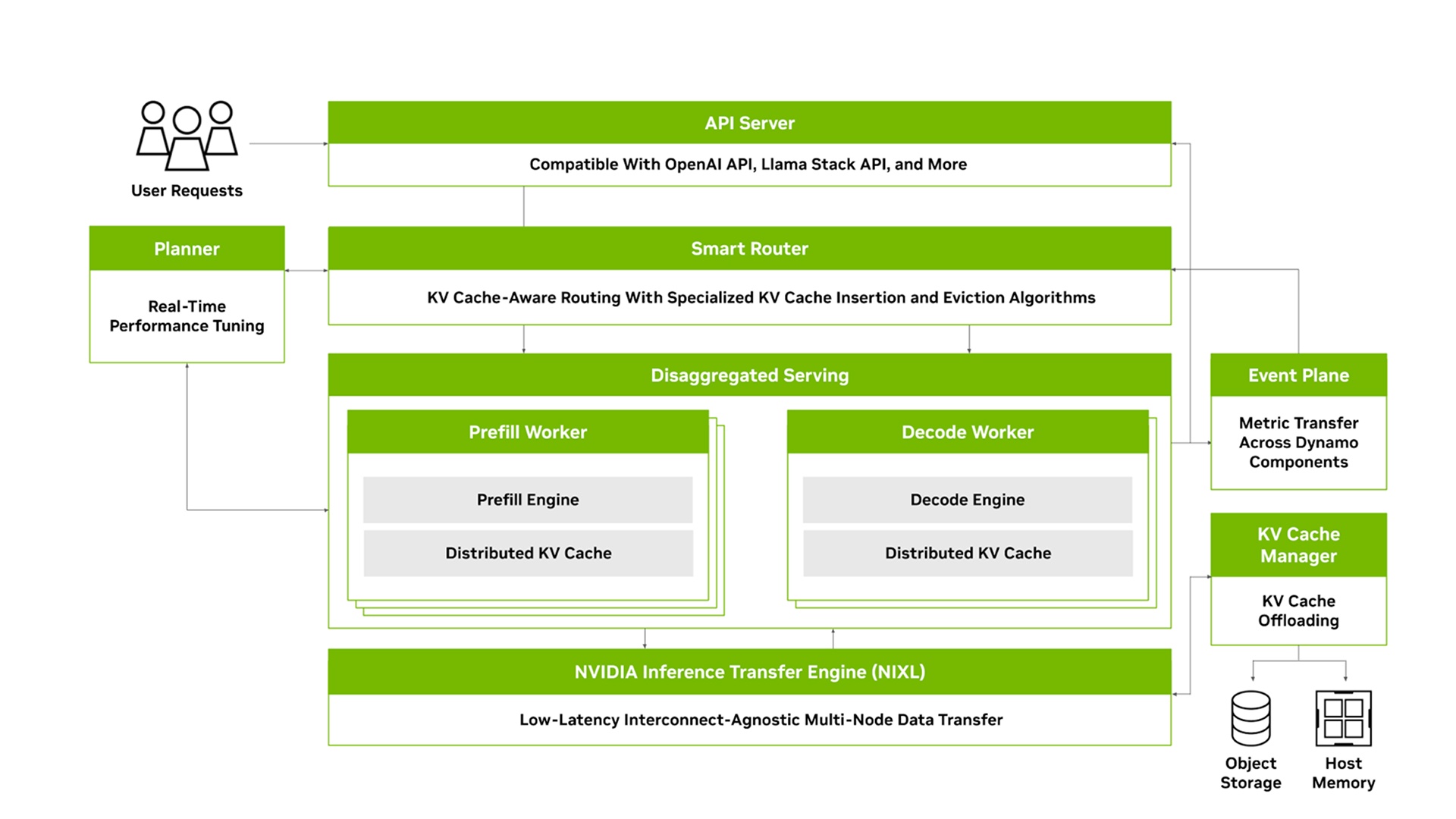
NVIDIA Dynamo 是一个开源、低延迟的模块化推理框架,用于在分布式环境中服务生成式 AI 模型。它通过智能资源调度和请求路由、优化的内存管理和无缝的数据传输,实现跨大型 GPU 集群的推理工作负载无缝扩展。NVIDIA Dynamo 支持所有主要的 AI 推理后端,并提供专门针对大语言模型 (LLM) 的优化,例如分解服务。 下载文档 了解 NVIDIA Dynamo 的实际应用了解如何快速设置和部署 NVIDIA Dynamo观看视频 观看采用 NVIDIA Dynamo 的 KV 缓存感知型智能路由观看视频 了解 NVIDIA Dynamo 如何实现分解服务观看视频 NVIDIA Dynamo 的工作原理模型变得越来越大,并且越来越集成到需要与多个模型交互的 AI 工作流中。大规模部署这些模型涉及将它们分布在多个节点上,需要跨 GPU 进行仔细的协调。随着推理优化方法(如分解服务)的出现,复杂性也会增加,分解服务会将响应分散到不同的 GPU 上,从而增加了协作和数据传输方面的挑战。 NVIDIA Dynamo 解决了分布式和分解推理服务的挑战。它包括四个关键组件: GPU 资源规划器:一个规划和调度引擎,用于监控多节点部署中的容量和预填充活动,以调整 GPU 资源,并在预填充和解码之间分配这些资源。 智能路由:KV 缓存感知路由引擎,可在多节点部署中高效引导大型 GPU 集群中的传入流量,从而最大限度地减少昂贵的重新计算。 低延迟通信库:先进的推理数据传输库,可加速 GPU 之间以及异构内存和存储类型之间的 KV 缓存传输。 KV 缓存管理器:成本感知型 KV 缓存卸载引擎,旨在跨各种内存层次结构传输 KV 缓存,在保持用户体验的同时释放宝贵的 GPU 内存。
观看录制视频,了解 NVIDIA Dynamo 的关键组件和架构,以及它们如何在分布式环境中实现无缝扩展和优化推理。 快速入门指南 了解开始使用 NVIDIA Dynamo 的基础知识,包括如何在分解的服务器设置中部署模型以及如何启动智能路由器。 入门博客 了解 NVIDIA Dynamo 如何帮助简化生产环境中的 AI 推理、有助于部署的工具以及生态系统集成。 使用 NVIDIA Dynamo 和 vLLM 部署 LLM 推理 NVIDIA Dynamo 支持所有主要后端,包括 vLLM。查看教程,了解如何使用 vLLM 进行部署。 查找适合的许可证,以为所选平台上的应用部署、运行和扩展 AI 推理。 NVIDIA Dynamo 在 GitHub 上以开源软件的形式提供,并附带端到端示例。 前往 NVIDIA Dynamo 资源库 (Github) NVIDIA AI Enterprise 将包含用于生产推理的 NVIDIA Dynamo。获取免费许可证,使用现有基础架构在生产环境中试用 NVIDIA AI Enterprise 90 天。 申请 90 天许可证联系我们,详细了解 NVIDIA Dynamo 入门套件访问有关预填充优化、解码优化和多 GPU 推理等推理相关的技术内容。 多 GPU 推理 模型规模不断扩大,无法再适应单个 GPU。部署这些模型需要在多个 GPU 和节点之间分配这些模型。此套件分享了用于多 GPU 推理的关键优化技术。 预填充优化 当用户向大语言模型提交请求时,它会生成 KV 缓存,以计算对请求的上下文理解。此过程的计算量非常大,需要进行专门的优化。此套件提供用于推理的基本 KV 缓存优化技术。 解码优化 在 LLM 生成 KV 缓存和第一个 token 后,它将进入解码阶段,并在此阶段以自回归方式生成剩余的输出 token。此套件重点介绍了解码过程的关键优化技术。
NVIDIA 认为可信 AI 是一项共同责任,我们已制定相关政策和实践,以支持在各种应用中开发 AI。根据我们的服务条款下载或使用此模型时,开发者应与其支持的模型团队合作,确保此模型满足相关行业和用例的要求,并解决不可预见的产品滥用问题。 立即开始使用 NVIDIA Dynamo 立即下载 (责任编辑:) |